博文
R语言中演示最大似然法的小例子
||||
R语言中演示最大似然法的小例子
熊荣川
六盘水师范学院生物信息学实验室
http://blog.sciencenet.cn/u/Bearjazz
在统计学中,通常我们观察的样本呈一定的分布。而各种分布都有自身的参数,调整这些参数值能得到最优的分布形态以拟合我们的样本分布。通常这种参数的调整,或者说找到最优的参数是用最大似然法实现的。利用参数的似然值方程,遍历参数的取值区间得到一个最大似然值,这个最大似然值对应的参数就是最优参数。下面我们就以指数分布来作些最基本的演示。
一个指数分布的概率密度函数是:
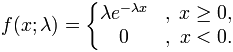
其中λ > 0是分布的一个参数,常被称为率参数(rate parameter)。指数分布的区间是[0,∞)。 如果一个随机变量X 呈指数分布,则可以写作:X ~ Exponential(λ)。
因此指数分布中一个重要的参数就是λ,为了便于输入,下面我们将使用字母u来替代λ。
设一组样本为(x1,x2,……xn)服从指数分布,其对数似然值方程为
l(u) = n log(u) − u∑(xi). 最大似然值得估计就是使得l(u)取得最大值得u估计。
首先把这个估计方程写成一个R语言函数
|
> |
Rmlfun = function(x) { + sumx = sum(x) + n = length(x) + function(mu) n * log(mu) - mu * sumx + } |
函数名称为“Rmlfun” |
|
efun = Rmlfun(1:10) |
定义一个由1到10,10个正整数呈指数分布的区间 |
|
|
> |
efun(3) |
求u=3时的似然值 |
|
|
[1] -154.0139 |
似然值 |
|
|
|
|
|
|
efun2 = Rmlfun(20:30) |
定义一个区间在20到30之间的指数分布efun2 |
|
> |
efun2(3) |
求u=3时的似然值 |
|
|
[1] -812.9153
|
似然值小于efun(3)= -154.0139说明,区间1到10更符合参数u为3的指数分布,这是区间的最优估计 |
|
|
|
下面我们对u的最优值进行最优估计 |
|
|
|
|
|
> |
chob=function(x){ + for(i in 1:x) print(efun2(i)) + } |
在区间20到30上,输出u从1到x之间所有似然值 |
|
> |
chob(10) |
参数上限为10 |
|
|
[1] -275 [1] -542.3754 [1] -812.9153 [1] -1084.751 [1] -1357.296 [1] -1630.291 [1] -1903.595 [1] -2177.126 [1] -2450.831 [1] -2724.672 |
输出u从1到10的似然值 可见u=1为最优参数值 |
https://m.sciencenet.cn/blog-508298-552158.html
上一篇:在R语言中写几个小程序
下一篇:If语句在R语言数据判别中的作用