ВЉЮФ
[зЊди]вЛжжЛљгкПьЫйИЕРявЖБфЛЛЕФРЉЩЂФЃаЭЭМЯёаоИДЗНЗЈ
|||
вЛжжЛљгкПьЫйИЕРявЖБфЛЛЕФРЉЩЂФЃаЭЭМЯёаоИДЗНЗЈ
баОПБГОА
ЭМЯёаоИДЪЧЭМЯёБрМКЭЭМЯёИДджаЕФвЛИіживЊЖјЪЕгУЕФЮЪЬт,ЫќЪЧРћгУвбжЊВПЗжЕФЭМЯёзїЮЊЯШбщаХЯЂЃЌЭЦЖЯШБЪЇЧјгђВЂЩњГЩгыжмЮЇЯёЫиЧјгђНсЙЙЁЂЮЦРэКЭгявхвЛжТЕФФкШнЁЃШЛЖјЃЌдкгіЕНДѓУцЛ§бкФЄЛђИДдгЭМЯёгявхЪБЃЌДЋЭГЭМЯёаоИДЗНЗЈШБЗІИпВуДЮЕФЪгОѕРэНтЃЌФбвдЩњГЩЪгОѕБЦецЧвгявхКЯРэЕФВЙЖЁЁЃеыЖдетИіЮЪЬтЃЌЛљгкЩюЖШбЇЯАЕФаоИДЗНЗЈЭЈЙ§ДгЭМЯёжаЬсШЁЧГВуЬиеїКЭЩюЖШгявхаХЯЂЃЌгааЇЕиНтОіСЫРЇШХДЋЭГЗНЗЈЕФЬєеНЁЃОэЛ§ЩёОЭјТчПЩвдздЖЏЬсШЁЩюЖШЭМЯёЬиеїЃЌЬсИпаоИДЙ§ГЬЕФзМШЗадКЭТГАєадЁЃЕЋгЩгкОэЛ§ЩёОЭјТчжЛФмбЇЯАОжВПЧјгђЬиеїЃЌдкШЋОжШкКЯЭМЯёЕФЩЯЯТЮФаХЯЂЗНУцДцдкОжЯоадЁЃвђДЫЃЌБОЮФЬсГіСЫвЛжжЛљгкПьЫйИЕРявЖБфЛЛЕФРЉЩЂФЃаЭЃЈFFT-DMЃЉгУгкЭМЯёаоИДЁЃОпЬхЖјбдЃЌFFT-DMРћгУШЅдыРЉЩЂИХТЪФЃаЭЃЈDDPMЃЉЬсШЁШЋОжНсЙЙаХЯЂВЂЩњГЩЭМЯёЯШбщЃЌВЂРћгУОэЛ§ЩёОЭјТчЬсШЁОЁПЩФмЖрЕФЯИНкаХЯЂЁЃЮЊСЫНјвЛВНдіЧПИУФЃаЭЕФгааЇадКЭаЇТЪЃЌЮвУЧНЋПьЫйИЕРявЖБфЛЛв§ШыРЉЩЂФЃаЭЃЌДгЭМЯёжаЬсШЁЦЕгђаХЯЂЃЌвддіЧПИажЊФмСІЃЌЬсИпЭМЯёаоИДЕФБэеїФмСІЁЃЪЕбщНсЙћБэУїЃЌFFT-DMдкЖЈадЗжЮіКЭЖЈСПЗжЮіЩЯвбОЛёЕУСМКУЕФаоИДадФмЁЃ
ГЩЙћНщЩм
ЮїББЙЄвЕДѓбЇЬяДКЮАИБНЬЪкПЮЬтзщЃЌЪзДЮЬсГівЛжжЛљгкПьЫйИЕРявЖБфЛЛЕФРЉЩЂФЃаЭЃЈFFT-DMЃЉВЂгУгкЭМЯёаоИДЁЃбаОПГЩЙћЗЂБэгкJournal of Cyber-Physical-Social Intelligence 2022ФъЕквЛОэЕквЛЦкЃКYuxuan Hu, Hanting Wang, Cong Jin, Bo Li, Chunwei Tian. "A Diffusion Model with A FFT for Image Inpainting" Journal of Cyber-Physical-Social Intelligence 2022, 1, 60-69. doi: 10.61702/MTPG8588.
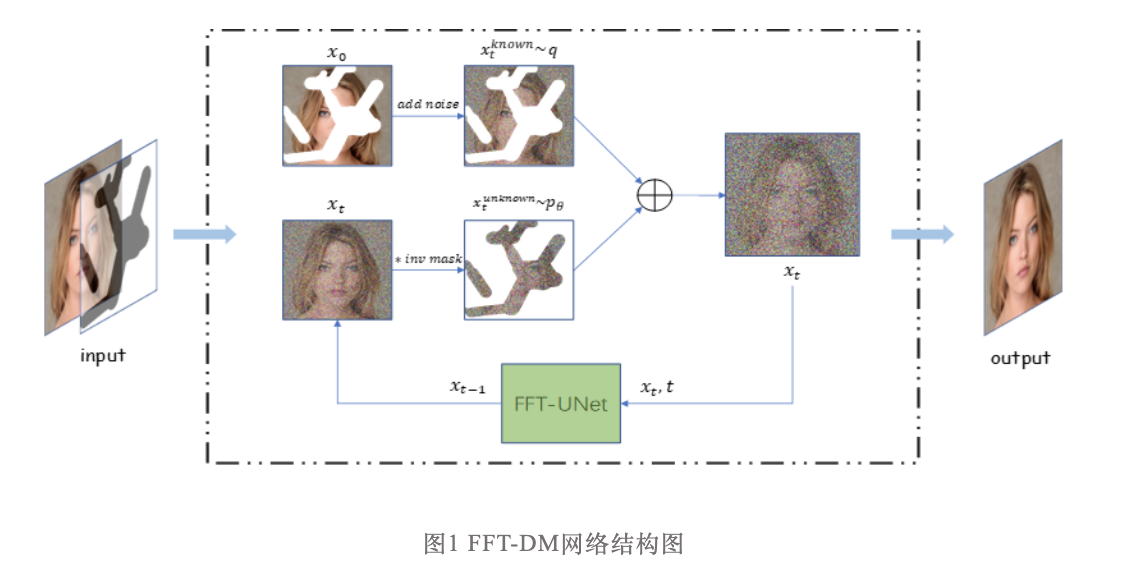
FFT-DMЕФЭјТчНсЙЙЭМШчЭМ1ЫљЪОЁЃЖдгкецЪЕЭМЯё![]() ЃЌБОЮФМйЩш
ЃЌБОЮФМйЩш![]() БэЪОЮДжЊЯёЫиЃЌ
БэЪОЮДжЊЯёЫиЃЌ![]() БэЪОвбжЊЯёЫиЃЌВЂдквбжЊЧјгђЩЯНјааИпЫЙВЩбљВЂЩњГЩЭМЯё
БэЪОвбжЊЯёЫиЃЌВЂдквбжЊЧјгђЩЯНјааИпЫЙВЩбљВЂЩњГЩЭМЯё![]() ЃЌШЛКѓНЋЦфгыЮДжЊЧјгђ
ЃЌШЛКѓНЋЦфгыЮДжЊЧјгђ![]() НсКЯЃЌЕУЕНDDPMФцЙ§ГЬдкЪБМфВНжш t ЕФЪфШы
НсКЯЃЌЕУЕНDDPMФцЙ§ГЬдкЪБМфВНжш t ЕФЪфШы![]()
![]()
![]() ЁЃ
ЁЃ
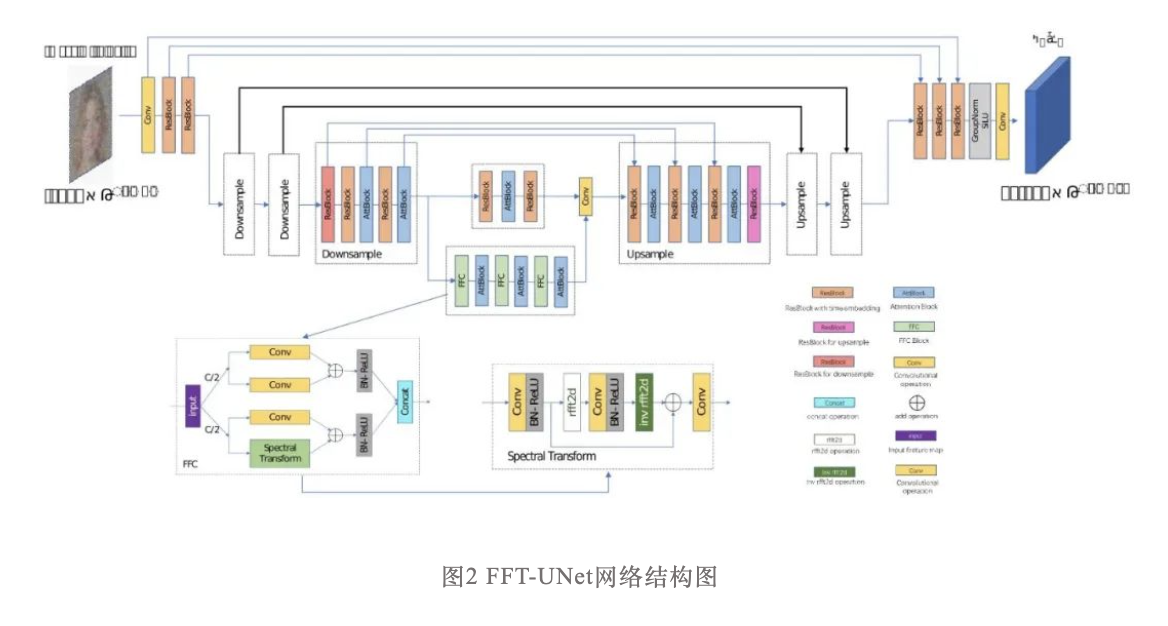
FFT-UNetЕФНсЙЙШчЭМ2ЫљЪОЃЌЫќБЛгУРДНЈФЃИпЫЙЗжВМ![]() ЃЌвддЄВтЦфВЮЪ§
ЃЌвддЄВтЦфВЮЪ§![]() КЭ
КЭ![]() ЃЌШЛКѓЖджаМфЭМЯё
ЃЌШЛКѓЖджаМфЭМЯё![]() НјааИпЫЙВЩбљЃЌЕУЕНФцЙ§ГЬдкЪБМфВНжш t ЕФЪфГі
НјааИпЫЙВЩбљЃЌЕУЕНФцЙ§ГЬдкЪБМфВНжш t ЕФЪфГі![]() ЁЃОпЬхЖјбдЃЌЮвУЧдкUNetЕФbottleneckВПЗжВЂСЊСЫвЛИігЩПьЫйИЕРявЖОэЛ§ЃЈFFCЃЉКЭзЂвтСІЛњжЦзщГЩЕФФЃПщЃЌВЂЭЈЙ§вЛИі1ЁС1ОэЛ§НЋЭЈЕРЪ§НЕЮЊдРДЕФ64ЭЈЕРЪ§ЁЃИУЩшМЦЪЧеыЖдДѓВПЗжОэЛ§ЩёОЭјТчИаЪмвАгаЯоЕФЮЪЬтЬсГіЃЌФПЕФЪЧЬсШЁЪфШыЭМЯёЕФЦЕгђаХЯЂВЂЬсЙЉживЊЕФШЋОжЩЯЯТЮФаХЯЂЃЌвддіЧПФЃаЭЖдЭМЯёећЬхНсЙЙаХЯЂЕФРэНтЃЌНјЖјЬсИпЭМЯёаоИДаЇЙћКЭТГАєадЁЃ
ЁЃОпЬхЖјбдЃЌЮвУЧдкUNetЕФbottleneckВПЗжВЂСЊСЫвЛИігЩПьЫйИЕРявЖОэЛ§ЃЈFFCЃЉКЭзЂвтСІЛњжЦзщГЩЕФФЃПщЃЌВЂЭЈЙ§вЛИі1ЁС1ОэЛ§НЋЭЈЕРЪ§НЕЮЊдРДЕФ64ЭЈЕРЪ§ЁЃИУЩшМЦЪЧеыЖдДѓВПЗжОэЛ§ЩёОЭјТчИаЪмвАгаЯоЕФЮЪЬтЬсГіЃЌФПЕФЪЧЬсШЁЪфШыЭМЯёЕФЦЕгђаХЯЂВЂЬсЙЉживЊЕФШЋОжЩЯЯТЮФаХЯЂЃЌвддіЧПФЃаЭЖдЭМЯёећЬхНсЙЙаХЯЂЕФРэНтЃЌНјЖјЬсИпЭМЯёаоИДаЇЙћКЭТГАєадЁЃ
БОЮФЬсГіЕФЗНЗЈдкCelebA-HQЛљзМЪ§ОнМЏЩЯГЌЙ§СЫКмЖрСїааЕФЗНЗЈЃЌШчЃКEdgeConnectЁЂDeepFill v2ЁЂAOT-GANКЭLaMaЕШЁЃЯъЯИЕФЭМЯёаоИДНсЙћШчБэ1ЫљЪОЃК

ЮЊСЫДгЪгОѕбщжЄБОЮФЬсГіЗНЗЈЕФгааЇадЃЌБОЮФжЦзїСЫ2зщПЩЪгЛЏЭМЯёЁЃШчЭМ3ЫљЪОЃЌЕквЛСаЮЊдЪМЭМЯёЃЌЕкЖўСаЮЊВЛЭЌбкФЄЯТЕФЭМЯёЃЌЕкШ§СаЮЊаоИДКѓЕФЭМЯёЁЃНсЙћБэУїЃЌFFT-DMПЩвдДІРэШЮвтаЮзДКЭГпДчЕФбкФЄЃЌдкгіЕНДѓГпДчЕФбкФЄЪБвВФмБэЯжСМКУЁЃДЫЭтЃЌЭМ4ЯдЪОFFT-DMПЩвдЩњГЩгыжмЮЇЧјгђЕФЮЦРэКЭгявхвЛжТЕФЖрбљЛЏЬюГфЧјгђФкШнЁЃетдйДЮЫЕУїЬсГіЕФFFT-DMЖдЭМЯёаоИДШЮЮёгааЇЁЃ

НсТл
дкБОЮФжаЃЌзїепУЧЬсГіСЫвЛжжЛљгкПьЫйИЕРявЖБфЛЛЕФРЉЩЂФЃаЭЭМЯёаоИДЗНЗЈЃЌFFT-DMЁЃИУЗНЗЈЩњГЩЕФФкШнВЛНідкЮЦРэЩЯгыжмЮЇЧјгђвЛжТЃЌЖјЧвдкгявхЩЯвВФмгыжмЮЇЧјгђБЃГжвЛжТЁЃ
FFT-DMЪЙгУРЉЩЂФЃаЭдіМгбкФЄЕФздгЩЖШЃЌВЂЩњГЩгыдЪМЭМЯёЕФгявхКЭЮЦРэЬиеїЯрЦЅХфЕФЭМЯёЯШбщЁЃЫцКѓЃЌFFT-DMРћгУUNetМмЙЙдкDDPMЕФФцЙ§ГЬжаВЖзНИќЖрЕФЮЦРэЬиеїКЭЯъЯИаХЯЂЁЃДЫЭтЃЌПьЫйИЕРявЖБфЛЛЛњжЦБЛШкШыЕНРЉЩЂФЃаЭжаЃЌвдЭкОђЦЕгђЬиеїВЂЬсЩ§ФЃаЭИажЊФмСІЁЃДѓСПЪЕбщжЄУїЃЌFFT-DMВЛНіФмЙЛЩњГЩОпгаИпЪгОѕжЪСПЕФаоИДЭМЯёЃЌВЂЧвФмЦНКтЭМЯёаоИДаЇЙћКЭаЇТЪЁЃНгЯТРДЃЌзїепУЧМЦЛЎНЋFFT-DMРЉеЙЕНДІРэЖрИіЕЭМЖЪгОѕШЮЮёЃЌШчЭМЯёШЅдыКЭШЅФЃК§ЁЃ
зїепМАЭХЖг

КњгъаљЃЌжаФЯДѓбЇМЦЫуЛњПЦбЇгыММЪѕзЈвЕВЉЪПбаОПЩњЃЌбаОПЗНЯђАќРЈЭМЯёШЅдыЁЂЭМЯёаоИДКЭЩюЖШбЇЯАЕШЁЃвбЗЂБэбЇЪѕТлЮФ3ЦЊЃЌЪкШЈЗЂУїзЈРћ1ЯюЁЃ

ЭѕхЋіЊЃЌЮїББЙЄвЕДѓбЇШэМўЙЄГЬзЈвЕБОПЦЩњЃЌбаОПЗНЯђАќРЈЭМЯёаоИДКЭЩюЖШбЇЯАЕШЁЃ

НљДЯЃЌжаЙњДЋУНДѓбЇИБИпМЖЙЄГЬЪІЃЌжївЊбаОПЗНЯђЮЊШЫЛњЛьКЯБэбнЁЂЧПЛЏбЇЯАКЭвєРжШЫЙЄжЧФмЁЃФПЧАЕЃШЮCAAI TransЁЂFITEEЕШжЊУћЦкПЏЕФПЭзљБрМЃЌвдМАCAAIЪРНчвєРжШЫЙЄжЧФмДѓЛсЁЂбЧжоШЫЙЄжЧФмДѓЛсЁЂICCSIЕШЙњМЪЛсвщЕФТлЬГжїЯЏМАГЬађЮЏдБЛсЮЏдБЁЃ

РюВЈЃЌЮїББЙЄвЕДѓбЇНЬЪкЃЌВЉЪПЩњЕМЪІЃЌжївЊДгЪТЖргђаХЯЂаЭЌгыжЧФмОіВпСьгђЕФбаОПЁЃЯжШЮЮїББЙЄвЕДѓбЇЯЕЭГгыПижЦЙЄГЬЯЕжїШЮЃЌЁАЗЩааЦїзлКЯЬхаЇФмЗжЮіЁБЙњМвЙњМЪПЦММКЯзїЛљЕиИБжїШЮЃЌУёУЫЮїЙЄДѓЮЏдБЛсУиЪщГЄЁЃдкЁЖCAAI Transactions on Intelligence TechnologyЁЗЁЂЁЖRemote SensingЁЗЁЂЁЖDefence TechnologyЁЗЁЂЁЖКНПебЇБЈЁЗЁЂЁЖгюКНбЇБЈЁЗЁЂЁЖБјЙЄбЇБЈЁЗЕШИпЫЎЦНЦкПЏЗЂБэбЇЪѕТлЮФ100грЦЊЃЌЦфжаSCI/EIЫїв§40грЦЊЃЌЩъЧызЈ30грЯюЃЌЪкШЈ20грЯюЃЌзЊЛЏ2ЯюЁЃЕЃШЮЁЖБјЦїзАБИЙЄГЬбЇБЈЁЗИБжїБрЃЌЁЖDronesЁЗЁЖJournal of Cyber-Physical-Social IntelligenceЁЗБрЮЏЃЌжаЙњздЖЏЛЏбЇЛсЛьКЯжЧФмзЈЮЏЛсЮЏдБЃЌжаЙњШЫЙЄжЧФмбЇЛсШЫЙЄжЧФмгыАВШЋзЈЮЏЛсЮЏдБЃЌжаЙњШЫЙЄжЧФмбЇЛсЧрФъЙЄзїЮЏдБЛсЮЏдБЃЌжаЙњжИЛггыПижЦбЇЛсМЏШКжЧФмгыаЭЌПижЦзЈЮЏЛсЮЏдБЃЌУёУЫЩТЮїЪЁЮЏИпЕШНЬг§ЮЏдБЛсЮЏдБЁЃЕУЕНСЫПЦММВПЙњМЪКЯзїЯюФПЁЂЙњМвМЖзнЯђЕШЖрИіЙњМвжиЕуЯюФПЕФжЇГжЃЌВЮМгЙњМвздШЛПЦбЇЛљН№ЁЂКНПеПЦбЇЛљН№ЕШЖрИіЛљН№ЯюФПЃЌИіШЫЛёЙњЗРПЦММНјВННБЖўЕШНБ1ЯюЃЌЩТЮїЪЁИпЕШбЇаЃПЦбЇММЪѕНјВННБЖўЕШНБ1ЯюЕШЁЃ

ЬяДКЮАЃЌЮїББЙЄвЕДѓбЇИБНЬЪкМАПеЬьЕиКЃвЛЬхЛЏДѓЪ§ОнгІгУММЪѕЙњМвЙЄГЬЪЕбщЪвГЩдБЁЃШыбЁ2023КЭ2022ФъШЋЧђЧА2%ЖЅМтПЦбЇМвАёЕЅЁЂЖрЯюЪЁМЖШЫВХЁЂЖрЯюЪаМЖШЫВХЁЂЮїББЙЄвЕДѓбЇАПЯшаТаЧЁЂ2022ЪЁШЫЙЄжЧФмбЇЛсгХауВЉЪПТлЮФЁЂ2021ФъЩюлкЪаCCFгХауВЉЪПбЇЮЛТлЮФЁЂ2022ФъЙўЖћБѕЙЄвЕДѓбЇгХауВЉЪПбЇЮЛТлЮФЁЂ2021ФъЛЊЮЊШЋЧђЬьВХЩйФъЬиБ№УцЪдбћЧыЁЃбаОПЗНЯђЮЊЪгЦЕ/ЭМЯёИДдКЭЪЖБ№ЁЂЭМЯёЩњГЩЁЂЩюЖШбЇЯАЕШЁЃдкIEEE TNNLSЁЂIEEE TMMЁЂIEEE TSMCЁЂIEEE TGRSЁЂIEEE TIVЁЂPattern RecognitionЁЂNeural NetworksЁЂInformation SciencesЁЂInformation FusionКЭICASSPЕШЙњМЪЦкПЏКЭЙњМЪЛсвщЩЯЗЂБэТлЮФ60грЦЊЁЃ6ЦЊESIИпБЛв§ТлЮФЃЌ2ЦЊESIШШЕуТлЮФЁЂ4ЦЊЖЅПЏЗтУцТлЮФЁЂ5ЦЊЙњМЪГЌЗжБцСьгђBenchmark ListЁЂ1ЦЊТлЮФММЪѕБЛУРЙњвНбЇгАЯёЙЋЫОЙКТђЩЬгУЁЂ1ЦЊТлЮФММЪѕБЛШеБОЙЄГЬЪІгІгУгкЦЛЙћЪжЛњЩЯЕШЁЃЕЃШЮCAAI Transaction on Intelligence TechnologyЃЌ Dense TechnologyЕШЖрИіSCIЦкПЏЕФБрЮЏЁЃЙњМвздШЛЛљН№ЦРЩѓзЈМвЁЂЩЯКЃЪаПЦММзЈМвЁЂИЪЫрЧьбєЪаЪ§зжОМУЗЂеЙзЈМвЁЂЫежнЪаЭјТчгыаХЯЂЛЏзЈМвЁЂЫежнШЫЙЄжЧФмбЇЛсРэЪТЁЂШЋЙњбаОПЩњНЬг§ЦРЙРМрВтзЈМвПтзЈМвЕШЁЃ
https://m.sciencenet.cn/blog-2374-1417284.html
ЩЯвЛЦЊЃК[зЊди]IV TIV Joint WorkshopеїИхПЊЦєЃЁ
ЯТвЛЦЊЃК[зЊди]еыЖдЩэЗнжЄЮФБОЪЖБ№ЕФКкКаЙЅЛїЫуЗЈбаОП
ШЋВПзїепЕФОЋбЁВЉЮФ
ШЋВПзїепЕФЦфЫћзюаТВЉЮФ
- • [зЊди]ЁОаТЪщЫйЕнЁПжаЙњздЖЏЛЏбЇЛсМрЪТГЄЭѕЗЩдОЭХЖггЂЮФзЈжјЃКЁЖЦНааШЫПкгыЦНааШЫРрЁЗ
- • [зЊди]ЁОИпЖЫНЛСїЁПЙўШјПЫЫЙЬЙЙњМвПЦбЇдКЁЂЙЄГЬдКдКЪПзцТъЕЯЖћвЛаанАСйЮвдКВЮЙлНЛСї
- • [зЊди]IEEE TCSS Ек11Оэ2ЦкЭјПЏвбЗЂВМ, ОДЧыЙизЂЃЁ
- • [зЊди]ЁОЯВБЈЁПЁЖжЧФмПЦбЇгыММЪѕбЇБЈЁЗ14ЮЛБрЮЏШыбЁ2023ЁАжаЙњИпБЛв§бЇепЁБ
- • [зЊди]ЁОдЄИцЁПЮВнЛсвщиМЦЫуЮЪЬтЃКЪ§бЇЁЂЩёбЇКЭММЪѕЫМЯыЕФНЛжЏгыХізВ
- • [зЊди]ЁАЙњзжЭЗЁБЛњЦїШЫЕфаЭгІгУГЁОАУћЕЅЙЋВМЃЌжаПЦЛлЭиСНИіЯюФПШыбЁ