博文
微博de故事: 映射化简找朋友
 精选
精选
||||
(李伟钢 郑建亚) Google技术团队于2004年首次公开提出映射和化简(MapReduce)的信息处理和文档管理模型,而原Yahoo团队于2005年着手开发Hadoop开放系统,实现这种并行计算理念。这一梦之旅几经捻转,形成目前位于美加州的Greenplum商务智能和云数据专营企业,并与另一跨国大数据企业EMC有着千丝万缕的联系。
Greenplum的专家们在介绍Hadoop系统时,习惯用 “你应相识的朋友” (People You May Know)问题来解释大数据问题的计算工作量,在此基础上介绍映射和化简概念和Hadoop解决方案。
假设某社交圈有1亿人参与,平均每人有100位朋友,要为所有参与者通过其朋友找到最可能认识的新友人Top-X,这里的X可以是5、10、等小于100的数。图1是Milind B.老师年初在里约大数据暑假班上演讲时,介绍解决此类问题的普通算法。
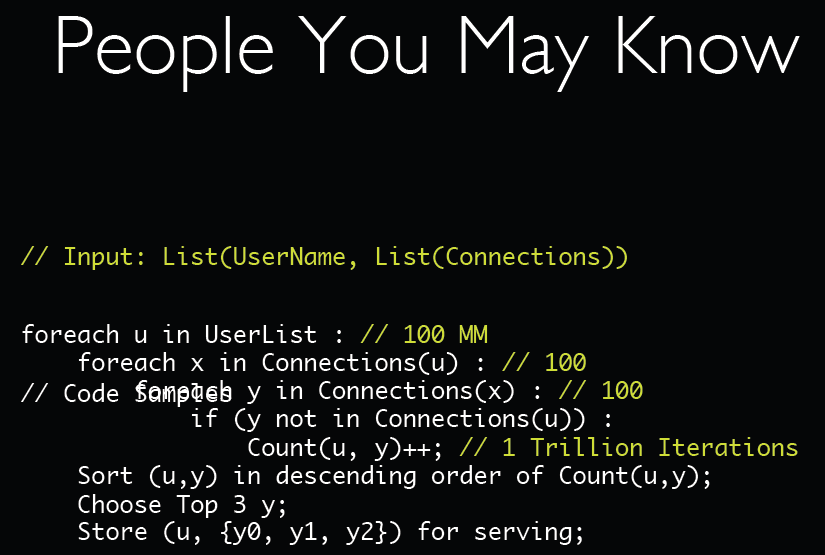
图1 Milind B.介绍的解决“你应相识的朋友”问题的普通算法。
执行该算法时,首先要遍历社交圈内的1亿人(u),每个TA(u)有100个朋友TA(x),如图1中的 connection(u),每个TA(x)又有自己的100个朋友TA(y),统计出现次数最多的(u,y),最后向每个TA(u)推荐前三名y1, y2, y3,这里Top-X,X=3。
对此算法进行分析,计算次数应为:108x100x100 = 1012。如果对每个友人进行101次随机访问,每次访问需要时间1ms,在每个友人的访问上需要100ms。假如使用一台电脑计算的话,对于一亿友人,这项工作的全部计算量大约需要100天。规范算法分析结果表明,该问题的计算复杂度为O(n3)。
对于现代人来说,是没这个耐心等上100天来参与这种社交活动。假若使用若干电脑并行计算如何?本文开头提到的开源软件框架ApacheHadoop,以Google的映射和化简模型为指导,实现对大数据的并行计算,查找有用的索引数据及其它“有价值”的信息,将此结果返回给相关用户。Hadoop支持4000个节点和PB级数据的数据密集型、分布式分析。
巴西利亚大学TransLab团队学习使用映射和化简模型解决“你应相识的朋友”问题。表 1列出使用映射和化简模型对“你应相识的朋友”问题的求解思路。
表 1 映射和化简模型对“你应相识的朋友”问题的求解思路

注意表1为笔者的读书札记,仅用于示意映射和化简模型思路,只列出u1 的少部分计算来说明算法,也就是说在u的用户集里,共需要进行1亿次这样的计算。结合图1和表1,解决该问题的在Hadoop系统环境下的算法重写为:
1)建立关系对过程。对于每个u建立(x,y) 关系对:xϵu且x是u的朋友,即存在connextion(u,x); y ϵu, 且y是x的朋友,即存在connextion(x,y), 暂时u和y不是朋友,即不存在connextion(u,y)。这里u为社交圈全部参与者,x为每个u的友人,y 为每个x 的友人。按“你应相识的朋友”问题的基本条件,u的数集为1亿,每个x和y的数集小于100。
2)映射(Map)过程。整理建立的关系对,映射(Map)出可能通过x建立的u 和y的关系,connection (u,y),的用户集列表(y1,(x1,x2,x3,...)),如表1中与u1可能建立关系的有,y1,y2,y3,y4等等。注意这里的限制条件是y≠x,即y不在connextion(u,x)集内。
3)化简(Reduce)过程。算出Connection(u,y)用户集,每个y与u通过x建立关系用户列表内的数量Count(u,y),如表1中的y1通过x1,x2,x3和u1认识,即渠道共有3个,等等。
4)排行过程(Rank)。对Connection (u,y)用户集内u 通过x 认识y 的用户数量Count(u,y)排行,列出前几名和x 联系最多的y,这些人都可以介绍给u。如表1中的Count(u,y)≥2,即Top-2, 应向u1推荐的新朋友为y1,y2,y3。
对于在线社交网络的微博平台,朋友推荐已经成为了一项不可缺少的功能和需求,对用户社交关系的后端分析,向用户推荐其可能认识的人,促进用户关系的建立,通过增加参与者之间的粘连性来增加用户对社交平台的忠诚度。
研究“你应相识的朋友”问题的目的在于将其推广到微博平台,进行在线即时和更为复杂的信息查询。后续博文将继续介绍TransLab团队把映射和化简理念与粉丝模型相结合,配置 Hadoop系统联机,从Twitter的75GB实际数据中查询Top-X的最新研究成果。敬请博友关注。
https://m.sciencenet.cn/blog-652078-674922.html
上一篇:一篇社交网络文章在OA期刊下载四百次
下一篇:周末家人午餐及巴西官食文化一瞥