博文
[转载]HISAT -- 一个具有低内存需求的快速剪接比对器
|||| |
HISAT(hierarchical indexing for spliced alignment of transcripts,转录本剪接比对分级索引)是一个比对来自RNA-Seq reads的高效系统。
HISAT使用一个基于Burrows-Wheeler变换和Ferragina-Manzini(FM)索引的索引方案,利用了两类索引进行比对:一个全基因组FM索引以定位每个比对,和许多局部FM索引用于非常快地扩展这些比对。
HISAT的人类基因组分级索引包含48,000个局部FM索引,每个索引代表了一个约64,000 bp的基因组区。
在真实和模拟数据集上的测试显示HISAT是当前可用的最快的系统,具有比任何其他工具等同或更好的准确性。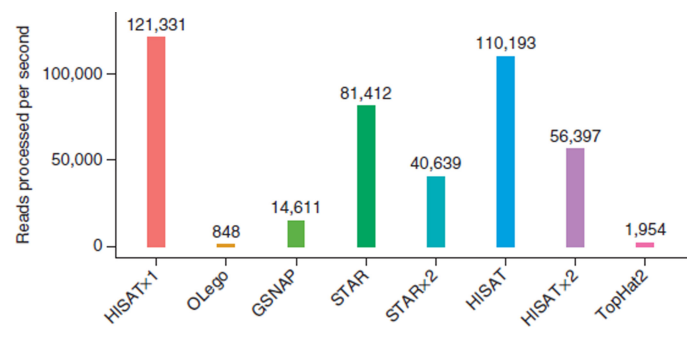
尽管它拥有大量索引,但是HISAT仅需要4.3GB的内存。HISAT支持任何尺寸的基因组,包括那些大于40亿碱基的基因组。
下载:http://www.ccb.jhu.edu/software/hisat/index.shtml
语言:C
参考:HISAT: a fast spliced aligner with low memory requirements
https://m.sciencenet.cn/blog-707141-1182578.html
上一篇:[转载]3Dmol.js -- 用WebGL进行分子可视化
下一篇:[转载]ngsCAT -- 评估靶向富集测序效率
扫一扫,分享此博文
全部作者的其他最新博文
全部精选博文导读
相关博文
- • Minerals线下恳谈会:履践致远、与时偕行——对话中国科学院广州地球化学研究所期刊合作学者
- • 聚英才 建高地 | 北京理工大学“特立青年学者”全球招聘开启
- • 700年后日本或濒临灭绝?日本学者推算预测:届时或仅剩1名15岁以下孩子
- • [转载]【同位素视角】非英语母语学者如何区分’e.g.’, ‘i.e.’, ‘namely’与‘such as’等混淆难题
- • 美国佐治亚大学等机构学者:刈割策略对Bulldog 805紫花苜蓿+Tifton 85狗牙根混播草地产量及品质的影响
- • 美国堪萨斯州立大学、密苏里大学等机构学者研究成果:土壤水分管理策略和品种多样性对紫花苜蓿产量、营养品质和农场盈利能力的影