博文
文献阅读笔记(18)-网页信息抽取实验系统设计
||||
网页信息抽取实验系统设计
本文主要概述硕士论文[1]的实验系统设计。本系统实现对中文网页的主题信息抽取,系统主要分为以下几个功能模块:DOM树构建模块、划分内容块模块、特征提取模块、相似度计算模块、聚类模块和主题信息识别模块。模块结构如图所示:

1. DOM 树构建模块 首先对网页进行标签规范化,使用CyberNeko HTMLParser。在将 HTML 语法进行规范化以后,网页被解析成一棵 DOM 树,以便于标签的遍历以及 VIPS 算法进行网页内容块的划分。该模块的输入为一个原始网页,输出为一棵 DOM 树。
2.划分内容块模块 该模块对输入的 DOM 树进行解析,利用 VIPS 算法,根据网页视觉特征对网页进行语义分块,在判断是否达到划分粒度要求时,需要一个阈值来控制,通过大量的研究和反复的实验验证,在 pDoC为 6 时分块效果最佳,因此将 pDoC设置为 6。
3.特征提取模块 对于每一个数据块,本文提取 12 个特征来表示,特征如下表所示:

本系统利用正则表达式来抽取出HTML源代码中的文本,因为特征提取的需要,我们最终的特征项为一个个独立的词,因此需要将各个数据块文本进行分词处理,本文采用了中科院的分词软件(ICTCLAS)进行中文分词。每一个网页被表示为一个n维向量(w1,w2,w3,…,wn),w代表该特征词的权值。使用TF-IDF函数来计算特征词的权重,公式如下:
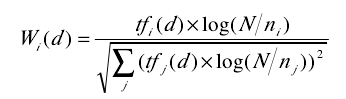
其中tfi表示该特征词在给定网页中出现的次数;ni表示出现该特征词的网页数量;N表示训练集中所含网页的总数。该模块的输入为网页数据块,输出为各个数据块的量化特征向量和文本特征向量。
4.相似度计算模块 任意两个数据块,首先根据余弦公式计算它们的量化特征向量相似度,然后计算文本特征相似度。假设 Bx和 By是两个可视数据块,Vx和 Vy是它们的可量化特征向量,那么 Bx和By之间的相似度Simxy计算方法如下:
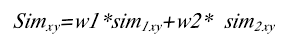
其中,sim1xy,sim2xy分别是数据块 Bx和 By之间的可量化特征相似度和文本特征相似度,w1 是可量化特征的权重,w2 是文本特征的权重。
5.聚类模块 本模块包括两个步骤:第一个步骤是相似数据块聚类,第二步是合并相似聚类。下图是聚类模块流程图:

参考文献
[1] 董娟.基于页面结构分析的网页信息抽取方法研究_董娟[J].中国石油大学, 2010, 硕士论文
https://m.sciencenet.cn/blog-719488-812551.html
上一篇:文献阅读笔记(17)-几个Extractor算法
下一篇:文献阅读笔记(19)-基于Crunch的网页内容提取的应用